Measuring and Visualizing Module Dependencies
We now have data and a method to visualize that data. But we still haven’t extracted any actionable information. To do that, we need to tighten up our definition of what we are looking for.
To recap, we are interested in making the dependency structure of programs more visible and using that structure to our advantage. So far we have set up some tooling for extracting the raw dependency data from Java programs built with Maven. Our next goal is to get that data into a form that we can analyze and work with.
Data Science and R
I’m neither a data scientist nor a statistician, but I know just enough to know that this sounds like a data science problem. Which means that everything we need probably exists, and it probably all exists in R.
And just like that, we have something approximating what we are looking for:
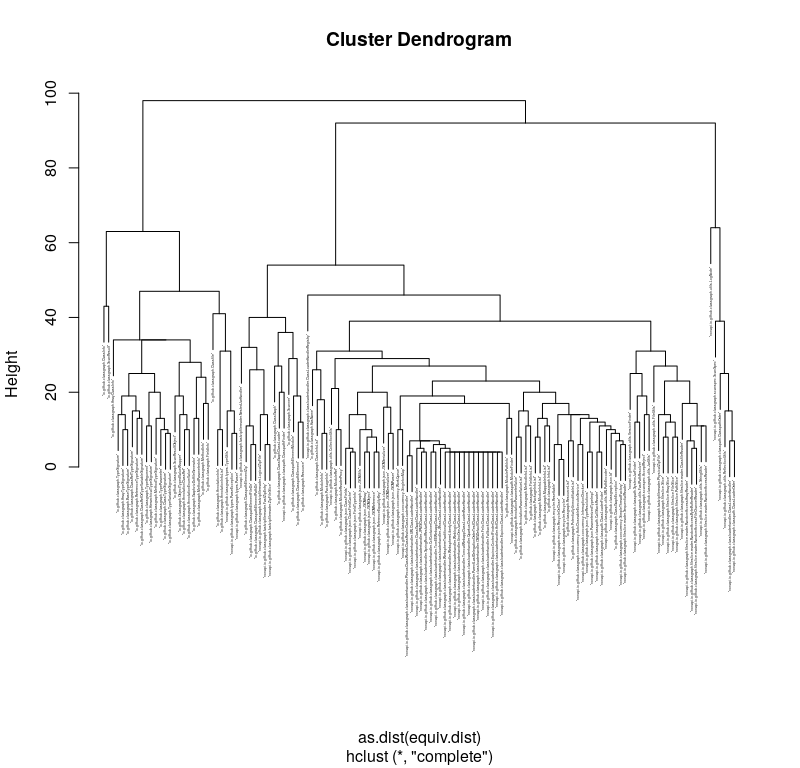
This is called a “dendrogram” and is used to display “hierarchical clusters”. Along the x-axis are the classes from our data. Each one forms a “cluster” of one class. If you follow the vertical line up from a cluster, you eventually hit a horizontal line. The horizontal line creates a new cluster by combining the clusters underneath it. The height of the line indicates how different the internal clusters are.
This representation maps quite easily to the filesystem. Horizontal lines would be directories, and the nodes would be files. So let’s do that transalation.
Dendrogram to Filesystem
The dendrogram data type is pretty simple. It is a binary tree where each node records the “difference” between its two children. The calculation of the difference is where all the magic happens, but for now we’ll just focus on the output. In our code, the calculated difference between the nodes will be the directory name.
Here is some pseudo-code describing the conversion from dendrogram to filesystem.
dendToFS <- function(input, currentDir) {
if (typeof(input) == "list") {
for (node in input) {
difference <- attr(dend[[x]], 'height')
dendToFS(node, currentDir + "/" + difference)
}
} else {
fileName <- attr(input, 'label)
file.copy(input, currentDir)
}
}If the input is a node, we get the calculated difference and append that to the destination path. If the input is a leaf, we get the file name and copy it from the source to the destination folder.
Connecting this with our maven plugin from last time, we can generate a new directory structure in just two commands,
$ mvn org.port67:auto-cluster-maven-plugin:dot -DbasePackages=io.github.classgraph,nonapi.io.github.classgraph
$ Rscript cluster.rWhich creates a fully operational copy of the project. You can run mvn clean install from the root and it will work just fine. Using the tree program to display the results,
$ tree ~/cluster-temp/classgraph/src/main/java
├── 63
│ ├── 43
│ │ ├── ClassInfo.java
│ │ └── ScanResult.java
│ └── 47
│ ├── 34
│ │ ├── 25
│ │ │ ├── 19
│ │ │ │ ├── 14
│ │ │ │ │ ├── 10
│ │ │ │ │ │ ├── ArrayTypeSignature.java
│ │ │ │ │ │ └── BaseTypeSignature.java
│ │ │ │ │ └── TypeSignature.java
│ │ │ │ └── 15
│ │ │ │ ├── 13
│ │ │ │ │ ├── ClassRefOrTypeVariableSignature.java
│ │ │ │ │ └── ReferenceTypeSignature.java
│ │ │ │ └── ClassRefTypeSignature.java
│ │ │ └── 20
│ │ │ ├── 11
│ │ │ │ ├── HierarchicalTypeSignature.java
│ │ │ │ └── TypeArgument.java
│ │ │ └── 13
│ │ │ ├── 10
│ │ │ │ ├── 9
│ │ │ │ │ ├── ClassTypeSignature.java
│ │ │ │ │ └── TypeVariableSignature.java
│ │ │ │ └── TypeParameter.java
│ │ │ └── MethodTypeSignature.java
...Based exclusively on the dependency information between classes, this is how the algorithm chose to group these files. This lines up remarkably well with the author’s naming schme. There are 134 source files, and “Signature” does not appear a single time outside of this group. “Type” only appears 5 more times.
This structure is a large part of how the compiler sees your code. It has to know in what order to compile source files, and then it must link all of them together to verify names and types match up. It also seems to be at least partly how the author sees this code. He wrote these classes to depend on each other, and he picked names that are closely related.
I have a hunch that most conversations that people have about “good” and “bad” code are really about this structure. But we don’t have a good set of tools for examining and manipulating it. So that’s what I’m trying to do here.
So Where to Next?
We now have a functional (albeit, somewhat silly) way of extracting the structure and applying it back to the source files. We’ll need to smooth out some of the rough edges so that using it is as painless as possible. Which means we’ll probably need to pick one language. I have more confidence that I can rewrite the R bits in Java, so we’ll go that route.
This means that we’ll have to break down the magic behind,
Previous Next